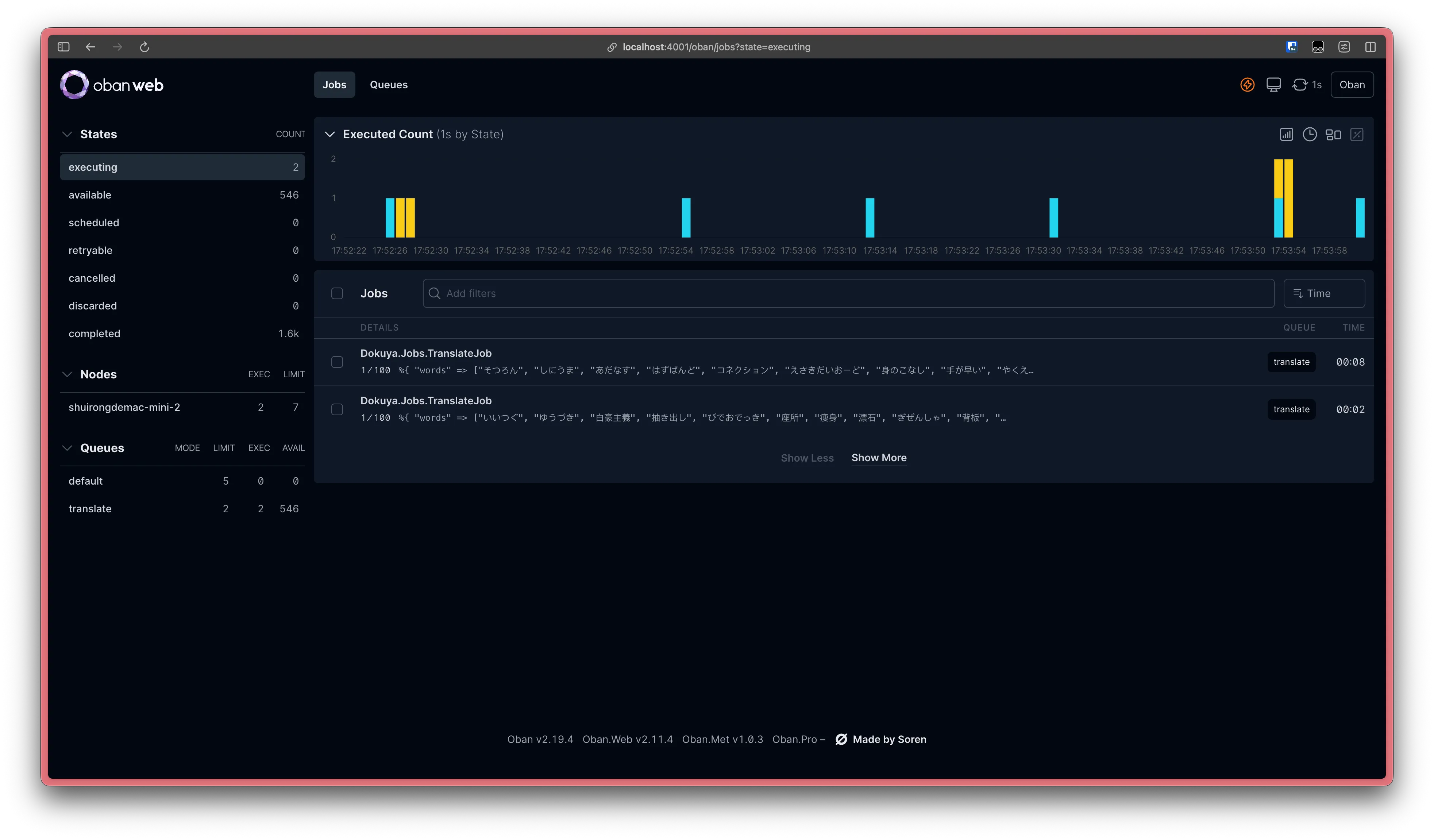
这个界面表明我的「单词批量翻译系统」正在稳定运行:
- 有 2 个翻译任务正在进行中
- 有 546 个翻译任务正在等待调度
- 有 1.6k 个翻译任务已完成
- 青色柱状图表明一个翻译任务顺利完成,黄色柱状图表明一个翻译任务失败,但未达到最大重试次数,因此稍后会重新尝试翻译。
稳定
这就是我现在的感受,我知道剩下的 546 个翻译任务最终都会顺利完成,我晚上可以睡得很好。
250000 个日语单词待翻译
在我上一篇博客:17751 部日本文学作品中有多少单词呢? 中,我得到了 114010 个日语单词。再加上从其他渠道获取到的 14 万个日语单词,我有 250000 个日语单词待翻译。
对于文本翻译,毫无疑问应该由 LLM 进行,而不是机器翻译,因为现在 LLM 的翻译质量非常不错,远超机器翻译。
但是,我又不想为这个事情花钱,因此我决定使用免费的 LLM API。在做了一些搜索后,我决定使用:Mistral AI 的服务(模型名为:mistral-medium-3-1-25-08),因为它的所有模型都可以免费使用,只不过有些限制:
- 每秒最大请求数:1
- 每分钟最大Tokens:500,000
- 每月最大Tokens:1,000,000,000
实际上在使用时,除了上面明确列出来的限制,偶尔还会遇到:3505 error(Service tier capacity exceeded for this model.),这应该是 Mistral 给 free tier 用户分配的 GPU 资源有限的原因。
这不是一件调用一下 API 就可以了的事情
可能会有人想:这不就是一件调用一下 API 就结束了的事情吗?将日文单词分组,排队调用 LLM API,然后等待翻译完成。
不,它不是。
或者说,理想情况下,可能是这样。但我们得考虑到复杂多变的现实。
我会遇到这些课题:
- LLM API 可能抛出错误(Code 500、Code 429…),所以我需要将失败的翻译任务重新执行(重试机制)
- LLM API 顺利完成(Code 200),但输出了不符合我要求的数据(我期望输出合法的 JSON 数据),需要检测出这种情况,丢弃掉该结果,然后重新执行(防范脏数据)
- 并发处理,以提高翻译效率(并发)
- 因为单词数量多,加上免费 LLM API 不会有很高的处理速度,预计翻译完所有内容需要很长时间。那就需要考虑程序被中断的可能(电脑关机、家中 WiFi 终端等因素),程序中断后,已完成的翻译内容、待处理的翻译任务、当前处理进度需要被妥善保存,后面可以方便地恢复中断前的状态(数据、状态持久化、中断恢复)
只有考虑到和解决掉这些课题的程序,才是健壮的,才能保证翻译任务可以顺利完成。而做完这些事情后,这个程序已经不能称之为“脚本”了,它完全可以被看作一个完整的系统。
选择合适的工具,工作可以很简单
上面的几个课题,基本是在作业系统的职责范畴内。因此,只要选择合适的作业系统即可,比如:Sidekiq(Ruby)、Celery(Python)。
而对于 Elixir,毫无疑问我们应该选择的作业系统是:Oban。
除了上面的 4 个课题外,Oban 还有很多功能。当然,Sidekiq、Celery也很强大、功能也很丰富。
但是 Oban 有一个绝对的优势:它由 PostgreSQL(还支持 MySQL、SQLite3) 驱动。数据库是大部分 Web 系统必不可少的核心组件,Redis(Sidekiq、Celery 依赖 Redis)并不是。
我现在已经有了一个 Phoenix 程序,连接 PostgreSQL 数据库。我想在当前的程序中添加一个「单词批量翻译系统」。很简单,在 mix.exs 中新增一个依赖项即可。而不用再安装一个 Redis。
Oban的安装文档中还有一些其他配置需要遵循。在使用 Oban 前,请查看文档。
{:oban, "~> 2.20"}
然后追加一个 Worker 模块,在里面实现翻译逻辑。
defmodule Dokuya.Jobs.TranslateJob do
use Oban.Worker, queue: :translate, max_attempts: 100, unique: true
require Logger
@impl Oban.Worker
def perform(%Oban.Job{
args: %{
"words" => words
}
}) do
case chat(words) do
{:ok,
%{
choices: [
%{
"finish_reason" => "stop",
"message" => %{
"content" => content
}
}
]
}} ->
JSON.decode!(content)
File.write!(
"./output/#{DateTime.utc_now() |> DateTime.to_string()}.json",
content
)
{:error, reason} ->
Logger.error("翻译失败, #{inspect(reason)}")
{:error, reason}
end
end
@impl Worker
def backoff(_) do
1
end
defp chat(input_json) do
MistralClient.chat(
model: "mistral-medium-2508",
temperature: 0,
prompt_mode: nil,
messages: [
%{
"role" => "user",
"content" => """
你是一名精确的日语到中文术语翻译助手。只返回符合给定 JSON Schema 的内容,不要输出任何额外文字或解释。
将下列日语词语精准翻译成简体中文,务必遵守:
1. meaning 字段 ≤6 个汉字,可用常见缩写或固定搭配。
2. 译文需自然、易懂,保留原义;不确定时写“待确认”。
3. 保持顺序与输入一致,text 字段原样照抄。
4. 仅输出 JSON,禁止附加说明、代码块或额外文本。
5. 不要添加和删除原始日文词语,保持数量相同。
输入(JSON 数组,每项为待翻译文本):
#{input_json}
"""
}
],
response_format: %{
type: "json_schema",
json_schema: %{
name: "translation",
description: "日语词语与中文含义(<=6个字符)的对应数组",
strict: true,
schema: %{
title: "translation_list",
type: "array",
items: %{
type: "object",
properties: %{
text: %{
title: "text",
type: "string"
},
meaning: %{
title: "meaning",
type: "string"
}
},
required: ["text", "meaning"],
additionalProperties: false
}
}
}
}
)
end
end
代码很简单,可以看出来我仅仅调用了一下 LLM API 而已。实现健壮系统的背后工作,全部由 Oban 完成了!👏
对于防范脏数据,我的做法只是在保存数据前加了一行:JSON.decode!(content) 而已。它的作用是,如何接口返回的内容不是有效JSON,这句代码就会抛出异常,从而导致当前翻译任务失败,Oban 会自动安排重试。下一次 LLM 大概率会返回有效 JSON 数据,如果依旧失败?没关系,我设置了最大重试次数:100 😂
将数据转换成 Oban 后台任务的代码也非常简单,而且,使用了 Elixir 管道操作符的代码看上去很干净、美观:
alias Dokuya.Jobs.TranslateJob
alias Dokuya.Repo
"words.txt"
|> File.read!
|> String.split(",", trim: true)
|> Enum.chunk_every(100)
|> Enum.map(fn words ->
%{
words: words
}
|> TranslateJob.new
|> Repo.insert
end)
选择合适的工具,工作可以很简单。